Web Scraping in Python Using Beautiful Soup


Vilius Dumcius
Last updated -
In This Article

Ready to get started?
Web scraping typically involves two key tasks: getting data from the web and extracting valuable information out of it. For the first one, Python users typically use a library like Requests , while for the second, Beautiful Soup is frequently used.
This article will explore Beautiful Soup’s extensive range of features, covering both basic and advanced functionality. In addition, you’ll learn how to use the various features of the library to scrape Books to Scrape , a sandbox website for learning web scraping that displays a list of books and their prices.
Setup
Beautiful Soup is a Python library, so you’ll need Python installed on your machine. If you don’t have it already, you can get it from the official downloads page.
In addition to that, you’ll need to install the Requests and Beautiful Soup libraries. You can do that with the following commands:
pip install requests
pip install bs4
Create a new folder, and create a new Python file called soup.py inside it. Then, open it in your favorite code editor and import the libraries at the top.
import requests
from bs4 import BeautifulSoupDownloading HTML
Beautiful Soup can parse the HTML code of a site and extract valuable information out of it. But to do that, you first need to get the HTML code of the site. For that, developers usually use Requests .
Requests is an HTTP client library, which means that it can communicate with HTTP servers and get information from them, just like a regular browser would.
For example, here’s how you can get the HTML code of Books to Scrape.
r = requests.get("https://books.toscrape.com/")
print(r.content)This should print out a large batch of HTML in your console. Of course, if you want to get the information inside it, you’ll need to parse it to get rid of all the unnecessary parts. This is where Beautiful Soup comes in.
(For more information on the Requests library and how it works, read our in-depth guide on python requests module 🧑🎓)
Parsing HTML
To start using Beautiful Soup, you need to take the HTML code you received from requests.get() and parse it.
soup = BeautifulSoup(r.content, "html.parser")This will parse the website HTML into an easily searchable object.
Finding Elements in HTML
Now, you can use the library to locate the HTML elements you need in the library. One of the ways to do that is via the find method. It locates the first element that matches a given query.
Try adding the following to your soup.py file:
h3 = soup.find("h3")
print(h3)Running it will print out the first h3 element of the page.
<h3><a href="catalogue/a-light-in-the-attic_1000/index.html" title="A Light in the Attic">A Light in the ...</a></h3>You can also find elements by class or by id. For example:
product = soup.find(class_="product_pod")
print(product)The code above will find the first element with the class of product_pod.
<article class="product_pod">
<div class="image_container">
<a href="catalogue/a-light-in-the-attic_1000/index.html"><img alt="A Light in the Attic" class="thumbnail" src="media/cache/2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg"/></a>
...Once you have an element, you can extract information from this element using attributes like text.
h3 = soup.find("h3")
title = h3.text
print(title)This will return the text of the first H3 heading, which is the displayed title of the first book.
A Light in the ...To get the displayed titles of all the books on the page, you can use the find_all method. Instead of returning just one result, it returns a list of all matching elements.
h3s = soup.find_all("h3")You can further iterate over that list using a for loop or list comprehension.
titles = [h3.text for h3 in h3s]
print(titles)Which returns the following result:
['A Light in the ...', 'Tipping the Velvet', 'Soumission', 'Sharp Objects', 'Sapiens: A Brief History ...', 'The Requiem Red', 'The Dirty Little Secrets ...', 'The Coming Woman: A ...', 'The Boys in the ...', 'The Black Maria', 'Starving Hearts (Triangular Trade ...', "Shakespeare's Sonnets", 'Set Me Free', "Scott Pilgrim's Precious Little ...", 'Rip it Up and ...', 'Our Band Could Be ...', 'Olio', 'Mesaerion: The Best Science ...', 'Libertarianism for Beginners', "It's Only the Himalayas"]There’s just one issue: titles sometimes get shortened when they are displayed on the page.

But if you look at the HTML, you’ll see that the full title is stored in the title attribute of the anchor tag that’s inside the H3.
<h3><a href="catalogue/a-light-in-the-attic_1000/index.html" title="A Light in the Attic">A Light in the ...</a></h3>To extract it, you need to:
- Move from the h3 inside the anchor tag.
- Access the title attribute of the anchor element using the get method.
Here’s the code that does that:
titles = [h3.a.get("title") for h3 in h3s]CSS Selectors
In addition to methods like find and find_all, Beautiful Soup offers support for CSS selectors.
CSS selectors are a versatile and widely supported method for locating specific HTML elements. Compared to other element selection methods, CSS selectors offer broader functionality, making them an invaluable tool in a web scraper’s arsenal.
You can use CSS selectors via the select function, which takes a string (CSS selector) and returns a list of elements that match this selector.
Querying a single tag works the same as when using find_all.
h3s = soup.select("h3")But CSS selectors offer much more flexible capabilities through the use of combinators and pseudo-classes.
Combinators
There are four combinators in CSS selectors, but the most useful in web scraping are descendant combinator (empty space) and child combinator (>). They can be used to match tags that are nested within other tags.
The difference between them is that the descendant combinator matches as many levels deep as it needs, while the child combinator only matches one level deep.
For example, you can use a child combinator to select all the anchor tags that are inside h3 tags.
anchors = soup.select("h3 > a")It will match all anchors that are inside H3 tags.
Pseudo-classes
In CSS, pseudo-classes are commonly used to denote a certain state of the element, such as when it is hovered over, clicked, etc.
But CSS selectors can select by a very cool pseudo-class called :nth-child which enables you to select an arbitrary child of an element by number or by some pattern such as repeating number, odd, or even.
For example, let’s say you want to get the name of the fifth category on the Books to Scrape website’s list of categories.
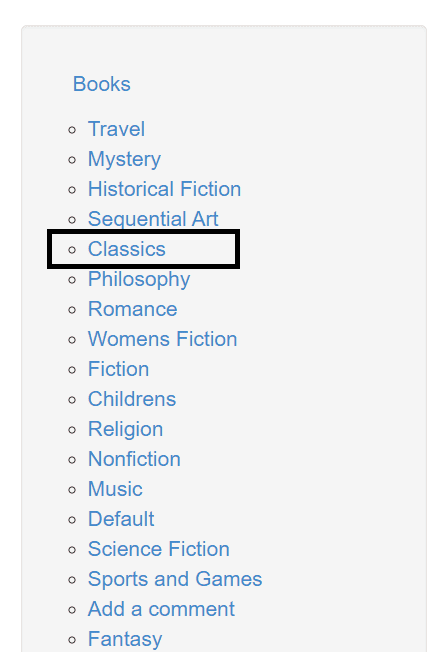
First, you need to locate the list using child selectors, and then you can extract the fifth element using the nth-child pseudo-class.
fifth_category = soup.select("ul.nav > li > ul> li:nth-child(5)")
print(fifth_category[0].text.strip())The code above should print out the name of the category—classics.
This can be very useful for websites where elements don’t use proper class names. In such a case, you can make web scraping scripts that depend on element order.
Scraping a Website with Beautiful Soup
Now that you’ve learned how to use the various features of Beautiful Soup, you can try to scrape the titles and prices of books from the Books to Scrape website.
Create a new file called books.py and import the libraries you’ll use:
import requests
from bs4 import BeautifulSoupAfter that, make a request to the website and parse the results.
r = requests.get("https://books.toscrape.com/")
soup = BeautifulSoup(r.content, "html.parser")Then find all the div elements surrounding individual books (they have the class of product_pod).
products = soup.find_all(class_="product_pod")Finally, you need to iterate over these elements to extract the necessary information.
books = []
for product in products:
title = product.find("h3").a.get("title")
price = product.find(class_="price_color").text
books.append({"title": title, "price": price})
print(books)The code above creates a new list called books. For each book, it:
- Extracts the title attribute of the anchor that’s inside the H3 tag.
- Extracts the price by finding its tag, conveniently marked with price_color, and extracting all the text that’s inside that tag.
It then creates a dictionary for the item and adds it to the book list.
Finally, it prints out all the books.
Running it with python books.py should return the following:
[{'title': 'A Light in the Attic', 'price': '£51.77'}, {'title': 'Tipping the Velvet', 'price': '£53.74'}, {'title': 'Soumission', 'price': '£50.10'}, {'title': 'Sharp Objects', 'price': '£47.82'}, {'title': 'Sapiens: A Brief History of Humankind', 'price': '£54.23'}, {'title': 'The Requiem Red', 'price': '£22.65'}, {'title': 'The Dirty Little Secrets of Getting Your Dream Job', 'price': '£33.34'} … ]Do You Need a Proxy with Beautiful Soup?
Beautiful Soup is a parsing library, which means that it doesn’t itself interact with the internet in any capacity—all it does is parse HTML using the selectors that you provide. But web scraping, of course, does involve the internet. And whenever you’re scraping the internet, you need to be careful about not raising the suspicion of website administrators.
For this reason, people that do web scraping typically use proxies. Proxies act as an intermediary between you and the site you’re trying to scrape, which helps to obscure your real IP address. If you manage to offend the owners of the website, they just ban the proxy and you can continue scraping the site.
A premium proxy solution like IPRoyal residential proxies will give you access to a rotating pool of proxies that will provide you a new IP on every request. Here’s how you can use them with the scraping setup that’s used in this article.
First, you need to find the link to your proxy. If you’re using IPRoyal, it’s conveniently located in the dashboard.
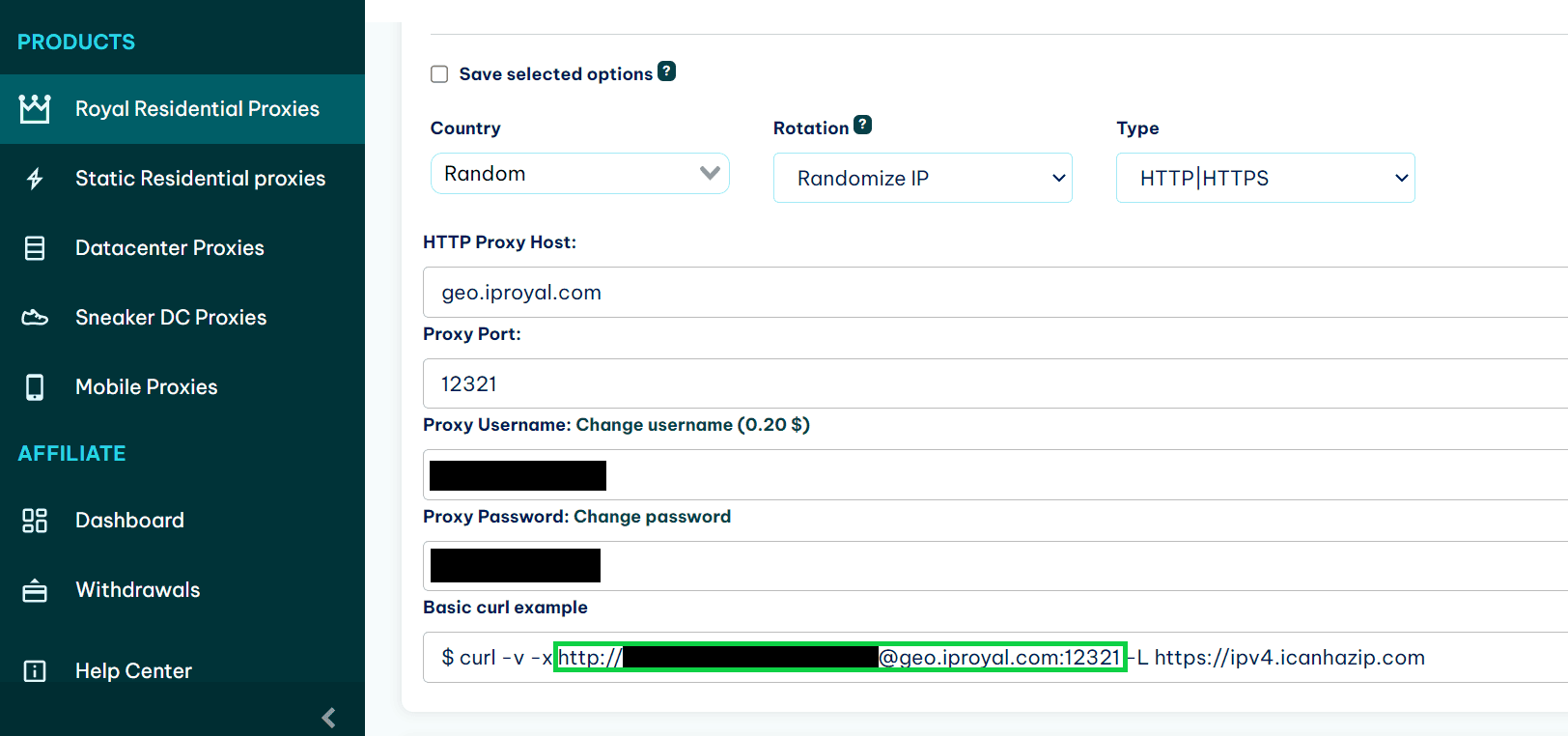
Then you need to add this link to your HTTP request that you make using Requests.
To do that, first create a dictionary that contains the link to your proxies, replacing the values with the link to your real proxy.
proxies = {
'http': 'link-to-proxy',
'https': 'link-to-proxy',
}
Then, add the proxy dictionary to the Requests calls that you’re making.
r = requests.get("https://books.toscrape.com/", proxies=proxies)Now your IP address will be properly protected and won’t be available to website owners.
Conclusion
Beautiful Soup is a very powerful web scraping tool, and it’s important to know how to use it. With the help of element locators and CSS selectors, it can easily tackle even websites that try to prevent web scraping by obscuring HTML.
But, of course, the Requests + Beautiful Soup approach is not suited for every web scraping task. Beautiful Soup can only parse HTML, which means that it cannot interact well with websites that use JavaScript. To parse these sites, you’ll need a more heavyweight tool like Selenium .
FAQ
How to click on items with Beautiful Soup?
Beautiful Soup is a parsing library, and so cannot interact with web elements the same way a browser would be able to. For basic navigation, you can use Beautiful Soup to extract the link of a website you will want to visit, and then use the Requests library to navigate to that link. This pattern can be useful for handling paginated websites, for example.
My Beautiful Soup scraper returns [] or None. What should I do?
In this case, you need to check whether your selectors / methods are correct for the HTML that you are trying to parse. Commonly, Beautiful Soup returns [] when there is no element that matches the given query, while None is returned when you try to access a property of an element that is not there.
How to get the text of an HTML element in Beautiful Soup?
Once you have located an HTML element, you can extract its text using the .text property.
Author
Vilius Dumcius
Product Owner
With six years of programming experience, Vilius specializes in full-stack web development with PHP (Laravel), MySQL, Docker, Vue.js, and Typescript. Managing a skilled team at IPRoyal for years, he excels in overseeing diverse web projects and custom solutions. Vilius plays a critical role in managing proxy-related tasks for the company, serving as the lead programmer involved in every aspect of the business. Outside of his professional duties, Vilius channels his passion for personal and professional growth, balancing his tech expertise with a commitment to continuous improvement.
Learn more about Vilius Dumcius

