How To Scrape Data From Glassdoor


Simona Lamsodyte
Last updated -
In This Article

Ready to get started?
Glassdoor is a review site that contains valuable data such as employee ratings for companies, employee feedback, salary ranges, job listings, and interview experiences.
But how can you access this data? There’s an easy way—web scraping! Read further to learn how to easily gather job listing data by scraping Glassdoor with tools like Python and Playwright.
What Are the Recommended Techniques for Scraping Data From Glassdoor?
When you try to use Glassdoor, you are soon met with a popup that requires you to submit information about a company that you work at in order to continue using the site. This might give an impression that it is hard to scrape the site, and that you need to use a complicated set of techniques to do that.
In fact, all the information is already in HTML when you request a page from Glassdoor. The popup only hides it for viewing via browser. By using a regular HTML parsing tool, you can easily extract this information and scrape the website.
One of the best tools to use for this purpose is Python together with the Playwright library for browser automation. Playwright enables you to mimic a real user doing actions in the web interface, which together with using proxies can be good enough for most scraping purposes.
How to Scrape Glassdoor Using Python
This tutorial will show you how to scrape Glassdoor job listings using Python and Playwright. The same technique can also be used to scrape employer data
Setup
To follow the tutorial, you’ll need to have Python installed on your computer. If you don’t already have it, you can use the official instructions to download and install it.
You’ll also need to install Playwright. Use the following commands to install the library and the browser engine that it needs.
pip install playwright
playwright install Create a new folder called glassdoor_scraper and create a file called glassdoor_scraper.py inside it. Open it in a code editor, and you’re ready to start.
Scraping the First Jobs Page
To scrape the web page, you first need to open it using Playwright. The following code opens a new browser and navigates to the job page on Glassdoor.
with sync_playwright() as pw:
browser = pw.chromium.launch(
headless=False,
)
context = browser.new_context(
viewport={"width": 1920, "height": 1080}
)
page = context.new_page()
page.goto(
'https://www.glassdoor.com/Job/index.htm')After navigating to the necessary page, you need to make the script fill out the search bars.
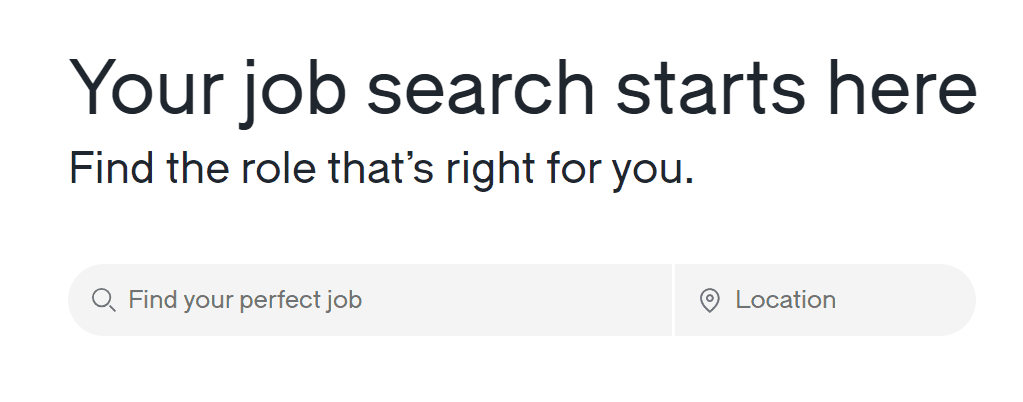
This can be accomplished with the code snippet below. It finds the job title textbox, types “Python developer” into it, then finds the country textbox, and types “Germany” into it. Then it presses the enter key and waits for the results to load.
For your purposes, you can change the “Python developer” and “Germany” strings to the job position and location you’re looking for.
job_textbox = page.get_by_placeholder("Find your perfect job")
job_textbox.type("Python developer")
location_textbox = page.get_by_label("Search location")
location_textbox.type("Germany")
page.keyboard.press("Enter")
page.wait_for_load_state('networkidle')After the results have loaded, you need to scrape the necessary information from job listings. The listings are teeming with data, but for the sake of brevity this tutorial will scrape only the following things:
- Title of the listing.
- Name of the company that published the listing.
- The company’s rating on Glassdoor.
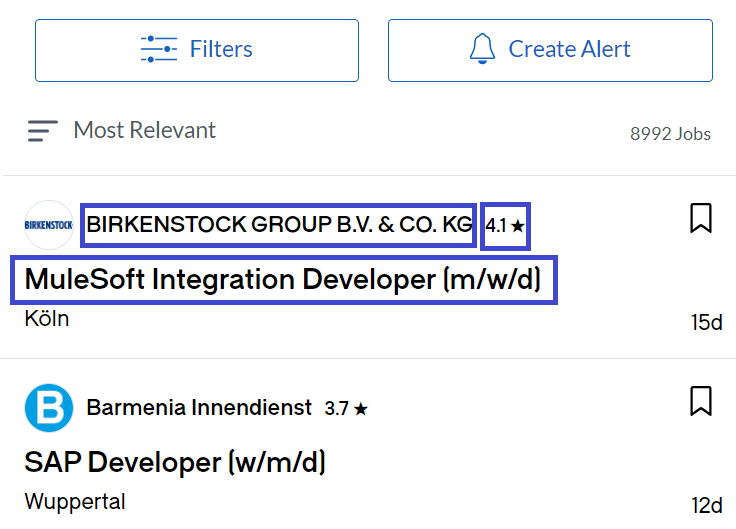
First, locate all the job cards on the page:
job_boxes = page.locator('a.jobCard').all() Then create a new array called jobs, and iterate over the job cards to scrape the information and populate the array.
For title and company, you can use regular CSS selectors, which are accessible with the locator() function.
For the rating, you can use the special get_by_text() function to locate an element that has the ★ symbol. Since some of the listings don’t have such an element, you should create an if-else statement that handles the missing piece.
for job_box in job_boxes:
title = job_box.locator('div.job-title').text_content()
if job_box.get_by_text("★").is_visible():
rating = job_box.get_by_text("★").text_content()
else:
rating = "Not available"
company = job_box.locator(
"[id^=job-employer]>div:nth-child(2)").text_content().split(rating)[0]
job = {"title": title, "company": company, "rating": rating}
jobs.append(job)
Finally, print out the array and close the browser:
print(jobs)
browser.close()Here’s the full script for convenience:
from playwright.sync_api import sync_playwright
with sync_playwright() as pw:
browser = pw.chromium.launch(
headless=False,
)
context = browser.new_context(
viewport={"width": 1920, "height": 1080}
)
page = context.new_page()
page.goto(
'https://www.glassdoor.com/Job/index.htm')
job_textbox = page.get_by_placeholder("Find your perfect job")
job_textbox.type("Python developer")
location_textbox = page.get_by_label("Search location")
location_textbox.type("Germany")
page.keyboard.press("Enter")
page.wait_for_load_state('networkidle')
job_boxes = page.locator('a.jobCard').all()
jobs = []
for job_box in job_boxes:
title = job_box.locator('div.job-title').text_content()
if job_box.get_by_text("★").is_visible():
rating = job_box.get_by_text("★").text_content()
else:
rating = "Not available"
company = job_box.locator(
"[id^=job-employer]>div:nth-child(2)").text_content().split(rating)[0]
job = {"title": title, "company": company, "rating": rating}
jobs.append(job)
print(jobs)
browser.close()It should print out a list of job listings such as this:
[{'title': 'Specialist Software Developer:in Python/C++ für mathematische Optimierungungen', 'company': 'Deutsche Bahn3.8 ★', 'rating': '3.8 ★'}, {'title': 'Web-Developer (m/w/d)', 'company': 'Allpersona GmbH', 'rating': 'Not available'} .. ]How Can Proxies Be Used to Enhance the Efficiency and Reliability of Glassdoor Scraping?
While scraping the front page of jobs in a certain country won’t trigger any anti-scraping measures from Glassdoor, it won’t stay that way if you will extend the scope of your web scraping. For example, if you want to gather a dataset of available positions for a certain job and a country over time, you will need to scrape a lot and run scripts rather frequently.
If you use the same IP address for large-scale web scraping like the one described, you might get interrupted by Glassdoor blacklisting your IP address. For this reason, web scrapers use proxies. They act as middlemen between the client and the service they want to scrape, enabling the client to hide their IP address and the amount of requests they are sending to the website.
A great option for scraping Glassdoor is to use residential proxies. They are proxies that originate from real IP addresses that are distributed all around the world. For this reason, they are not bound to trigger detection as much as proxies that come from a data center would.
Here’s how you can improve your code to add a proxy. The example code will use the IPRoyal residential proxy service , but you’re welcome to follow along if you already have a different proxy provider—there should be no big difference.
First, you will need to find the server, username, and password information for your proxy server.
If you’re using IPRoyal proxies, you can find this information in your dashboard—server is the concatenation of host and port fields.

Then, update the pw.chromium.launch() function with the data:
browser = pw.chromium.launch(
headless=False,
proxy={
'server':'host:port',
'username':'username',
'password': 'password123',
}
)Now all the requests from the Playwright session will be funneled through your chosen proxy server.
How to Scrape Glassdoor Without Coding?
Besides libraries written in programming languages like Python and JavaScript, there are a lot of no-code tools that you can use for scraping Glassdoor. While they don’t allow the same degree of customization and flexibility as a hand-written solution, they can be useful for complete beginners in web scraping.
By using these solutions, you can scrape data from Glassdoor in an intuitive manner.
Octoparse
Octoparse is a web scraping tool that allows users to extract data from websites without using any code. It provides a user-friendly interface that allows users to visually configure the scraping process. Users can point and click on elements of a webpage to define what data they want to extract, such as text, images, links, and more. The tool also offers various features to handle pagination, data transformation, scheduling, and exporting scraped data to various formats like Excel, CSV, or databases.
Apify
Apify is a platform and toolset that allows developers to easily automate web scraping, data extraction, and web automation tasks. It provides a range of tools and features to simplify the process of building and running web scraping and automation workflows.
Automatio
Automatio is an automation tool to extract data from websites. It provides a no-code interface that helps people without any coding skills build cloud-based web scrapers.
What Are the Legal Considerations When Scraping Data From Glassdoor?
Accessing public information on the internet in an automated manner is totally legal, and using proxies to hide your IP address is perfectly legal as well.
But when creating a Glassdoor account, you accept terms of use, which includes a clause that expressly prohibits web scraping. Therefore, there is a possibility that a Glassdoor account might be suspended or linked to your identity, which could lead to legal ramifications.
For this reason, it’s important to not log in while scraping Glassdoor and to use proxies while scraping.
Are There Any Limitations or Restrictions on Scraping Data From Glassdoor?
If you use a reliable proxy network, there are no restrictions on the amount of data you can scrape from Glassdoor. You’ll have unfettered access to company reviews, salary insights, job postings, and more. You can mine this treasure trove of data to discern market trends, gauge employee sentiments, or fine-tune your recruitment strategies.
FAQ
Is scraping data from Glassdoor allowed according to their terms of service?
Scraping data from Glassdoor is against its Terms of Use . It expressly forbids to “scrape, strip, or mine data from the services without our express written permission”. Fortunately, most of the pages that you might want to access are publicly available, which means that it is legal to scrape them. If you do not have an account, the only thing that Glassdoor can do is to blacklist your IP, which can be solved by using proxies .
Are there any rate limits or IP blocking measures in place for scraping data from Glassdoor?
There are no limits and measures publicly available. But if you plan to do large-scale scraping from one IP address, the traffic from it will definitely be flagged and the IP address will be suspended access or blacklisted. To prevent that, it’s important to use a rotating proxy that hides your real IP address and distributes traffic among different IP addresses to avoid detection.
Can I scrape reviews and ratings from Glassdoor using proxies?
Yes, using proxies to scrape reviews and ratings from Glassdoor is perfectly legal and possible, as long as you don’t use your own account for scraping. Scroll a bit up to see how it might be possible with IPRoyal residential proxies .
Author
Simona Lamsodyte
Content Manager
Equally known for her brutal honesty and meticulous planning, Simona has established herself as a true professional with a keen eye for detail. Her experience in project management, social media, and SEO content marketing has helped her constantly deliver outstanding results across various projects. Simona is passionate about the intricacies of technology and cybersecurity, keeping a close eye on proxy advancements and collaborating with other businesses in the industry.
Learn more about Simona Lamsodyte

