How To Scrape Data From Amfibi Business Directory


Milena Popova
Last updated -
In This Article

Ready to get started?
Amfibi is a business directory that provides information about various businesses in areas like advertising, finance, and information technologies.
By scraping the website, you can gain valuable data about business contact details, company descriptions, and more, which can be used for market research, lead generation, competitor analysis, and other business-related purposes.
This tutorial will show you how to scrape the website using Python libraries like Requests and Beautiful Soup .
Why Is Web Scraping Data From Amfibi Useful for Business Analysis and Lead Generation?
Amfibi contains a variety of basic data points on the businesses listed in its directory, including their names, contact details, industry classifications, and descriptions. This comprehensive data can serve as a valuable resource for businesses looking to understand their industry, identify potential partners, and assess the competitive landscape .
Furthermore, it’s easy to use it for things like market research, lead generation, and competitor analysis.
For example, by extracting contact information from Amfibi, such as email addresses, phone numbers, and physical addresses, businesses can generate leads for their sales and marketing efforts. Because the companies are sorted according to the industry, it’s easy to get hundreds of valuable contacts in your specific niche. And because the contact information comes with various kinds of data about the company, it’s easy to craft a well-targeted sales pitch.
Or, if you want to do market research for a new or existing business, scraping Amfibi allows businesses to gather data about companies operating in specific industries like advertising, finance, and information technologies. This information can be used to analyze market trends, identify emerging players, and assess market saturation.
What Are the Steps Involved in Scraping Data From the Amfibi Business Directory?
Scraping data from Amfibi is very simple. It’s a static website that doesn’t use any JavaScript for displaying content. Therefore, there is no need for any advanced web scraping tools or browser automation libraries.
To scrape it, all you need to do is download the HTML code of the web page you want to scrape using a HTTP client library like Requests. Afterwards, parse the HTML code using a library like Beautiful Soup to find the information that you need.
How Can Python Libraries Like Beautiful Soup Assist in Scraping Data From the Amfibi Business Directory?
Python libraries like Beautiful Soup can be extremely helpful in scraping data from Amfibi.
Beautiful Soup is a powerful parsing library that can be used for extracting data from website HTMLs. When used in combination with libraries that fetch data from the webpage, it provides a custom web scraping solution with zero hassle.
Scraping Amfibi With Beautiful Soup
In this tutorial, you’ll learn how to scrape Amfibi using easy-to-use Python libraries: Requests and Beautiful Soup.
Setup
To follow this tutorial, you need to have Python installed on your computer. If you don’t have it yet, follow the official instructions to download and install it.
After that, install the libraries necessary for the project with the following terminal commands:
pip install requests
pip install bs4 Finally, create a file called amfibi_scraper.py and open it with your favorite code editor such as Visual Studio Code .
Scraping a Business Page
In this section, you’ll learn how to scrape a business page from Amfibi. At the end, you’ll have a solution that takes an Amfibi business page and returns all the data in it as a Python dictionary.
As an example, this tutorial will use the business page of an agency called Ignite Creative.
First, import the libraries that you’ll use: Requests, Beautiful Soup, and time.
import requests
from bs4 import BeautifulSoup
import timeAfter that, get the HTML code of the page using Requests:
url = 'https://www.amfibi.com/us/c/7900137-0b8bcf80'
response = requests.get(url)Then, parse the HTML using Beautiful Soup. This will create a Python object that you can query with selectors:
soup = BeautifulSoup(response.text, 'html.parser') Finally, create an empty Python dictionary called business. You will populate this dictionary with data about the business during the process of scraping.
business = {}Now you can use selectors to find data that you need.
First, find the name of the business.
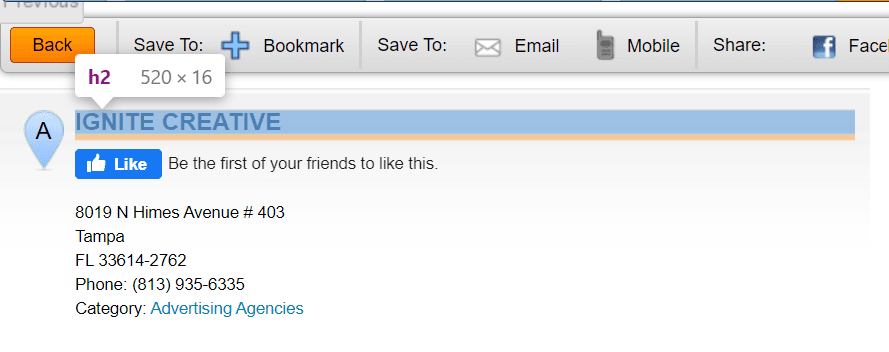
It’s the only h2 element on the page, so it can be selected with a CSS selector that targets h2’s.
After that, use .text to access the text content of the element and .strip() to delete any lingering whitespace. Finally, update the business dictionary with the business name information.
name = soup.select_one('h2').text.strip()
business.update({'Name': name})Finding the address of the business and getting it properly formatted is a bit harder.
You can get the address by running two subsequent queries on the page. First finds the first table element, the second finds the first p element inside that table element.
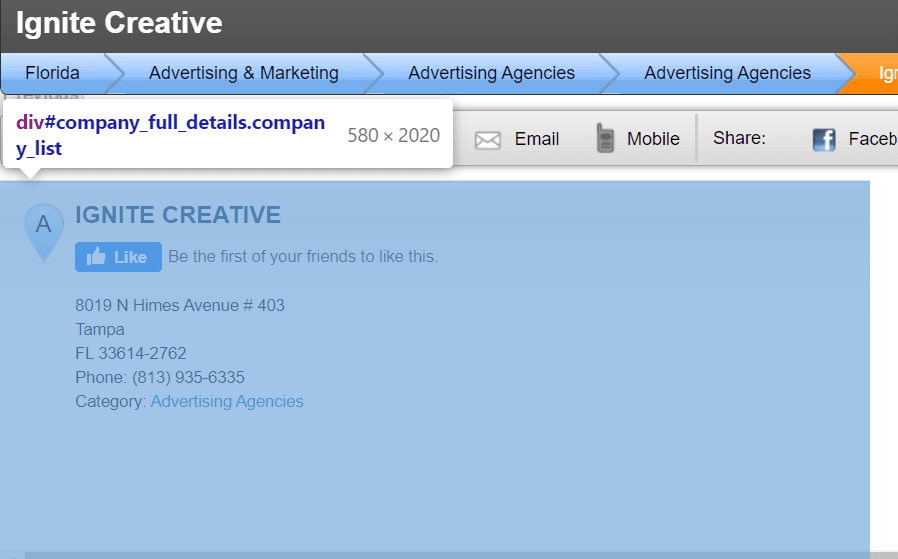
address = soup.select_one('table').select_one('p')Then you can format the address by:
- stripping the whitespace with
strip() - getting rid of unnecessary tabs in the middle with
replace() - and joining the items with commas using
replace()again.
address_string = address.text.strip().replace(
'\t', '').replace('\n', '').replace(' ', ', ')Finally, update the dictionary with the information:
business.update({'Address': address_string}) To get the individual information, first select all the data about the company by selecting the div element with the class company_list. It contains the whole table of data.
data = soup.select_one('div.company_list') Then select all the child div elements of the element:
table_items = data.findChildren('div', recursive=False) Iterate over the elements in table_items, extract the name and data of each item, and add them to the dictionary:
for table_item in table_items:
try:
title = table_item.select_one('div.sub_title').text.strip()
content = table_item.select_one('p').text.strip()
item = {title: content}
business.append(item)
except:
passThe function above uses the try/except mechanism to not fail on items that don’t fit the data format.
Finally, print the resulting Python dictionary:
print(business)Here’s the full code for convenience:
import requests
from bs4 import BeautifulSoup
import time
url = 'https://www.amfibi.com/us/c/7900137-0b8bcf80'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
business = {}
name = soup.select_one('h2').text.strip()
business.update({'Name': name})
address = soup.select_one('table').select_one('p')
address_string = address.text.strip().replace(
'\t', '').replace('\n', '').replace(' ', ', ')
business.update({'Address': address_string})
data = soup.select_one('div.company_list')
table_items = data.findChildren('div', recursive=False)
for table_item in table_items:
try:
title = table_item.select_one('div.sub_title').text.strip()
content = table_item.select_one('p').text.strip()
item = {title: content}
business.append(item)
except:
pass
print(business)Here’s an example of a result the script should return when called upon a page:
{'Name': 'Ignite Creative', 'Address': '8019 N Himes Avenue # 403, Tampa, FL, 33614-2762, Phone: (813) 935-6335', 'Location Type': 'Single Location', 'Revenue': '$125,000 - $150,000', 'Employees': '2', 'Years In Business': '17', 'State of incorporation': 'Florida', 'SIC code': '7311 (Advertising Agencies)', 'NAICS code': '541810 (Advertising Agencies)'}Are There Any Considerations or Challenges When Scraping Data From Amfibi Business Directory?
If you’re scraping a single item of data from the website and converting the results to a dictionary, your actions won’t make a blip on the total traffic on the website. But the most effective use of scraping the directory involves scraping many pages at once.
For example, you could create a script that opens up all the advertising agencies in one region and scrapes them for contact details, which would later be used for sending out bulk offers.
Unfortunately, this needs a different approach. Like any website owner, Amfibi monitors the traffic and tries to prevent traffic from IP addresses that use it too much. So, if you will try to open up 100s of connections to scrape information, or go through pages at blazingly fast speeds, your IP address will be marked and might be banned or suspended from use.
To solve this, web scrapers use proxies. Proxies act as a middleman between you and the server you’re connecting to. They take your request, and forward it to the server with a changed IP address.
If you’re using a reliable proxy provider like IPRoyal residential proxies , they will provide you with an ethically-sourced pool of IPs from all around the world. With services like these, you can have a different IP on every request that you make to the site. And because the IPs are sourced from regular customers and not data centers, the administrators of the website won’t be able to detect any web scraping activity based on IPs.
Adding a proxy to a script is simple and takes only a couple of lines of code: the next section will explain how.
How to add a proxy to a Python request?
To add a proxy to your Python request made with the Requests library, you first need to find the link that your proxy uses.
If you’re using IPRoyal residential proxies, you can find the link in your dashboard.
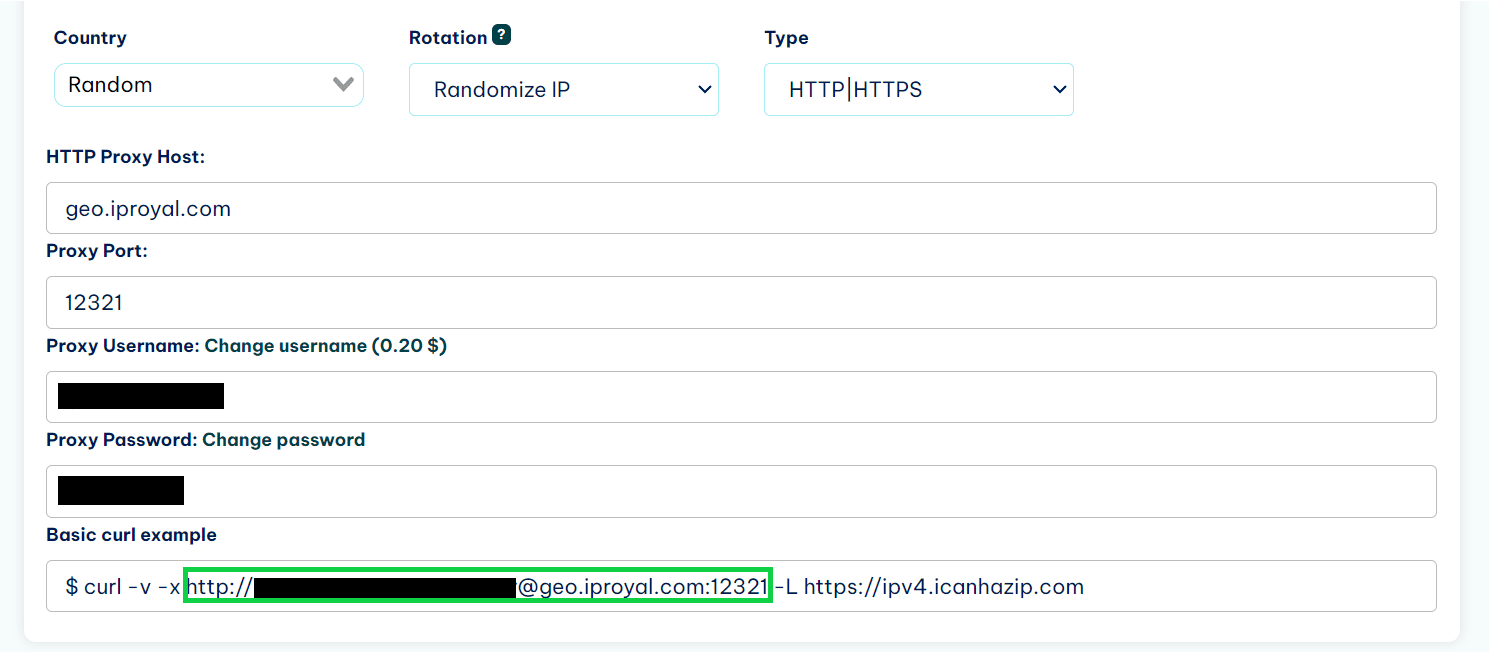
Then, create a proxies variable that holds that link.
proxies = {
'http': 'http://username:[email protected]:12321',
'https': 'http://username:[email protected]:12321',
}
Then, use the `proxies` variable in your `requests.get()` call:
```python
response = requests.get(url, proxies=proxies)Now the request will be handled by the proxy and the website won’t know your real IP address.
What Types of Business Data Can Be Scraped From the Amfibi Business Directory?
Each company profile contains lots of information, including:
1. Company details. These can include the company name and description of services that they offer.
2. Category. The directory categorizes businesses by industry.
3. Contact information. This might include the names and contact details of key individuals in the company, such as CEOs, owners, or managers.
4. Location. Location-specific data, such as the city, state, or country in which the business is located.
5. Financial information. In some cases, you may find revenue figures or other financial data, though this is less common.
6. Website links. Links to the business’s website, social media profiles, or other online presences.
7. Email addresses. Email addresses associated with the business.
No matter what your goal is, if it concerns companies that reside in the United Kingdom, the United States, or Australia, Amfibi can be a good resource to tap into for leads and market data.
Summary
With simple tools like Requests and Beautiful Soup, you can easily scrape valuable data from the Amfibi business directory. Furthermore, using proxies allows you to do large-scale web scraping on the website, enabling you to gather datasets on different industries that can be used for market research, lead generation, and competitor analysis.
To see more examples on how to scrape websites for valuable data, check out these tutorials on how to scrape Glassdoor and Expedia .
FAQ
Is web scraping data from Amfibi Business Directory allowed according to their terms of service?
At the date of publication, there is no statement that expressly prohibits scraping the website in Amfibi terms of service. Using web scrapers is also not forbidden in the robots.txt of the website.
But it doesn’t mean that the website cannot disable your access for heavy scraping activity. If you plan to scrape hundreds of companies, it’s wise to use a proxy service like IPRoyal residential proxies while scraping.
Can I scrape business names, addresses, and contact information from Amfibi Business Directory?
Yes, it’s possible to scrape all of this information and much more from the company pages in the Amfibi business directory.
Are there any restrictions on the number of requests or concurrent connections when scraping data from Amfibi Business Directory?
There are no explicit restrictions on the amount of requests or concurrent connections, but any website will prohibit many successive requests or concurrent connections from the same IP address. To fix this, it’s important to limit and slow down your scraping activities if a large amount of concurrent requests are not needed and also to use proxies to hide the amount of scraping that you’re doing.
Author
Milena Popova
Content Writer
With nine years of writing experience, Milena delivers exceptional content that informs and entertains readers. She is known for her reliability, efficiency, and cooperative nature, making her a valuable team player. Milena’s passion for IT and proxy networks fuels her content creation, ensuring accessibility for all. Outside of work, you’ll find her reading a good book or keeping up with the ever-evolving world of IT.
Learn more about Milena Popova

