Rust Web Scraping with Selenium


Gints Dreimanis
Last updated -
In This Article

Ready to get started?
While dynamic scripting languages like Python and JavaScript are the most common choices for web scraping projects, using a statically typed and compiled language like Rust can be useful as well for additional safety guarantees and increased performance.
In addition, it’s just fun to do web scraping with a new language for practice!
This tutorial will show you how to scrape dynamic pages in Rust with thirtyfour , Rust’s browser automation library that’s powered by Selenium .
If you’re just starting out with web scraping in Rust, we recommend reading our starter’s web scraping with Rust guide first.
What is Rust, and Why Should You Use It For Web Scraping?
Rust is a general-purpose programming language that’s especially suited for low-level tasks where squeezing the best performance for the buck is necessary.
It also has a rich type system that enables you to encode complex relationships via the combination of structs , enums , and traits . While web scraping is usually done in dynamically-typed languages, you can use the type system of Rust as a friend that makes sure that the resulting data will be as you expect.
What is Selenium?
Selenium is a collection of open-source projects for browser automation. With Selenium and its WebDriver API, you can remotely control a browser and make it do virtually any action that a user could do.
While Selenium (and its alternatives) are used mainly for testing , they can also be used to scrape dynamic web pages that reveal information only when loaded by a browser.
Tutorial: Scraping Quotes With Rust & Selenium
In this tutorial, you’ll learn how to use the thirtyfour library to scrape the mock quote app on Scraping Sandbox. It will show you how to take actions such as launching a browser, locating elements, clicking on things, typing, and scrolling.
Setup
Make Sure You Have Rust Installed
First, you’ll need to have Rust installed on your computer. If you don’t have it yet, you can follow the official instructions for installing it.
Download ChromeDriver and Run It
After that, you’ll also need to download a ChromeDriver that matches the version of Chrome you have on your computer (you can lookup the version in Settings -> About Chrome). After downloading, run it using the terminal.
This will create a WebDriver process that thirtyfour will use.
Setup a Rust Project
Finally, set up a new Rust project with the following command:
cargo new rust_scraperMove to the directory of the project and open the Cargo.toml file.
Add the following libraries to the list of dependencies:
[dependencies]
thirtyfour = "0.31.0"
tokio = "1.26.0"
Thirtyfour is the library that you will use for scraping. Tokio is Rust’s async runtime.
After you have set up the Rust project, open the src/main.rs file in a code editor.
Hello Selenium!
To start off, here’s a sample Rust program that uses Thirtyfour. It opens the quote website that we’ll scrape, waits a bit, and closes the browser.
To try it out, paste the code in main.rs and run the cargo run command in your terminal.
use thirtyfour::prelude::*;
use tokio::time::Duration;
#[tokio::main]
async fn main() -> WebDriverResult<()> {
let caps = DesiredCapabilities::chrome();
let driver = WebDriver::new("http://localhost:9515", caps).await?;
driver.goto("http://quotes.toscrape.com/scroll").await?;
tokio::time::sleep(Duration::from_secs(5)).await;
driver.quit().await?;
Ok(())
}
Let’s go through what it does step by step.
- First, it tells the library that you expect the browser you will be driving to be Chrome with DesiredCapabilities.
- Then, it connects to the WebDriver running on port 9515 of the machine (this is the port that ChromeDriver will use by default when you run it).
- After that, it opens a page with driver.goto() and waits for five seconds.
- Finally, it closes the browser.
If the code runs on your machine, you’re ready to start scraping the website.
Locating Elements
In this section, you’ll learn how to scrape the quotes displayed in the page.
Delete the following line from the script:
tokio::time::sleep(Duration::from_secs(5)).await;
In the place of this line, you’ll put the code for scraping data.
To scrape the quotes in the page, you first need to locate all the boxes containing quotes and then extract text out of them.

You can use the driver.find_all() and driver.find() functions to locate elements in the page. They take a wide variety of selectors such as CSS selectors , XPath , and more.
Here’s a function that locates all the “quote boxes” in the website.
let quote_elems = driver.find_all(By::Css(".quote")).await?;It does that by finding all the elements with the quote CSS class.
After selecting the boxes, you can loop over them to collect the information.
The code below takes each box, finds the elements with classes “text” and “author” inside it, and extracts the text of those elements. Then it stores them as a tuple in a vector.
let mut quotes = Vec::new();
for quote_elem in quote_elems {
let quote_text = quote_elem.find(By::Css(".text")).await?.text().await?;
let author = quote_elem.find(By::Css(".author")).await?.text().await?;
let quote = (quote_text, author);
quotes.push(quote);
}
Finally, you can print the quotes out in the console:
for quote in quotes {
println!("{} -- {}", quote.0, quote.1)
}
Here’s the full code:
use thirtyfour::prelude::*;
#[tokio::main]
async fn main() -> WebDriverResult<()> {
let caps = DesiredCapabilities::chrome();
let driver = WebDriver::new("http://localhost:9515", caps).await?;
driver.goto("http://quotes.toscrape.com/scroll").await?;
let quote_elems = driver.find_all(By::Css(".quote")).await?;
let mut quotes = Vec::new();
for quote_elem in quote_elems {
let quote_text = quote_elem.find(By::Css(".text")).await?.text().await?;
let author = quote_elem.find(By::Css(".author")).await?.text().await?;
let quote = (quote_text, author);
quotes.push(quote);
}
for quote in quotes {
println!("{} -- {}", quote.0, quote.1)
}
driver.quit().await?;
Ok(())
}
Scrolling the Page
You may have noticed that the page has an infinite scroll: once you scroll lower, new quotes appear. This is where the fact that you’re automating a real browser and not just a HTML parsing library can come in handy.
With the scroll_into_view() method, you can scroll the page down to the last quote, enabling you to load and scrape additional quotes.
For example, if you want to scroll down five times, you can do it with the following loop:
let mut quote_elems: Vec<WebElement> = Vec::new();
for _n in 1..5 {
quote_elems = driver.find_all(By::Css(".quote")).await?;
let last = quote_elems.last().unwrap();
last.scroll_into_view().await?;
tokio::time::sleep(Duration::from_secs(1)).await;
}
The code’s quite simple: it finds all the quote elements, scrolls down to the last element, and then waits a bit for new elements to load.
This is how it looks together with what we have:
use thirtyfour::prelude::*;
use tokio::time::Duration;
#[tokio::main]
async fn main() -> WebDriverResult<()> {
let caps = DesiredCapabilities::chrome();
let driver = WebDriver::new("http://localhost:9515", caps).await?;
driver.goto("http://quotes.toscrape.com/scroll").await?;
let mut quote_elems: Vec<WebElement> = Vec::new();
for _n in 1..5 {
quote_elems = driver.find_all(By::Css(".quote")).await?;
let last = quote_elems.last().unwrap();
last.scroll_into_view().await?;
tokio::time::sleep(Duration::from_secs(1)).await;
}
let mut quotes = Vec::new();
for quote_elem in quote_elems {
let quote_text = quote_elem.find(By::Css(".text")).await?.text().await?;
let author = quote_elem.find(By::Css(".author")).await?.text().await?;
let quote = (quote_text, author);
quotes.push(quote);
}
for quote in quotes {
println!("{} -- {}", quote.0, quote.1)
}
driver.quit().await?;
Ok(())
}
Interacting with Elements on the Webpage
Selenium also enables you to interact with other elements of the website.
For example, the website has a Login page . Since Selenium imitates a real browser, you can actually go and use it to log in!
First, you need to select the login button on the page. This is easiest done with an XPath selector that queries the text of the element.
let login_button = driver
.find(By::XPath("//a[contains(text(), 'Login')]"))
.await?;
The code above selects an anchor element that contains the text “Login”.
After that, you can click on it by using the click() method.
login_button.click().await?;Once the browser does that, it will get redirected to a login page, where a form needs to be filled out.

Then you can locate the form elements with the driver.find() method and use the send_keys() method to fill them out.
let username_field = driver.find(By::Css("#username")).await?;
username_field.send_keys("username").await?;
let password_field = driver.find(By::Css("#password")).await?;
password_field.send_keys("password").await?;
Finally, you can locate and click the submit button.
let submit_button = driver.find(By::Css("input[type=submit]")).await?;
submit_button.click().await?;
Here’s the full code for this section:
use thirtyfour::prelude::*;
#[tokio::main]
async fn main() -> WebDriverResult<()> {
let caps = DesiredCapabilities::chrome();
let driver = WebDriver::new("http://localhost:9515", caps).await?;
driver.goto("http://quotes.toscrape.com/scroll").await?;
let login_button = driver
.find(By::XPath("//a[contains(text(), 'Login')]"))
.await?;
login_button.click().await?;
let username_field = driver.find(By::Css("#username")).await?;
username_field.send_keys("username").await?;
let password_field = driver.find(By::Css("#password")).await?;
password_field.send_keys("password").await?;
let submit_button = driver.find(By::Css("input[type=submit]")).await?;
submit_button.click().await?;
driver.quit().await?;
Ok(())
}
Using Proxies with Thirtyfour
While web scraping is perfectly legal , it’s not encouraged by some web administrators. If they see that you are connecting to their website in an automatic way, they might decide to block your IP address from accessing the website.
That’s why it’s a good idea to use a proxy when doing web scraping. A proxy acts as an intermediary before the client and the server, changing the request so that it looks like it came from the proxy server and not the client.
If you use a proxy , the server cannot get hold of your real IP address and you won’t get banned, for example, from viewing YouTube videos on your computer for scraping the website. Instead, the proxy’s IP will be banned.
There are two kinds of proxies: free and paid. While free proxies don’t cost anything to use, they are frequently slow to use, limited in the amount of IPs offered, and might actually collect your private data to sell to other parties. Paid proxies like IPRoyal residential proxies provide a proxy pool with IPs from all around the globe and rotate proxy IPs on every request by default.
To add a proxy in thirtyfour, you need to use the set_proxy() method to add it to WebDriver’s capabilities.
First, import CapabilitiesHelper (which contains the method).
use thirtyfour::{prelude::*, CapabilitiesHelper};After that, adjust the capabilities after initializing them.
let mut caps = DesiredCapabilities::chrome();
caps.set_proxy(
thirtyfour::common::capabilities::desiredcapabilities::Proxy::Manual {
ftp_proxy: None,
http_proxy: Some("http://link-to-proxy.com".to_string()),
ssl_proxy: Some("http://link-to-proxy.com".to_string()),
socks_proxy: None,
socks_version: None,
socks_username: None,
socks_password: None,
no_proxy: None,
},
)?;
This will work for free proxies. Unfortunately, Selenium doesn’t work well with authenticated proxies since they need to fill out an authentication window that Selenium can’t access.
To use an authenticated proxy, the best (and definitely easiest) option is to whitelist your IP with your provider .
Here’s how you can do it with IPRoyal residential proxies. First, find your IP address via a tool like icanhazip.
Then go to the IPRoyal residential proxy dashboard and choose the Whitelist section.
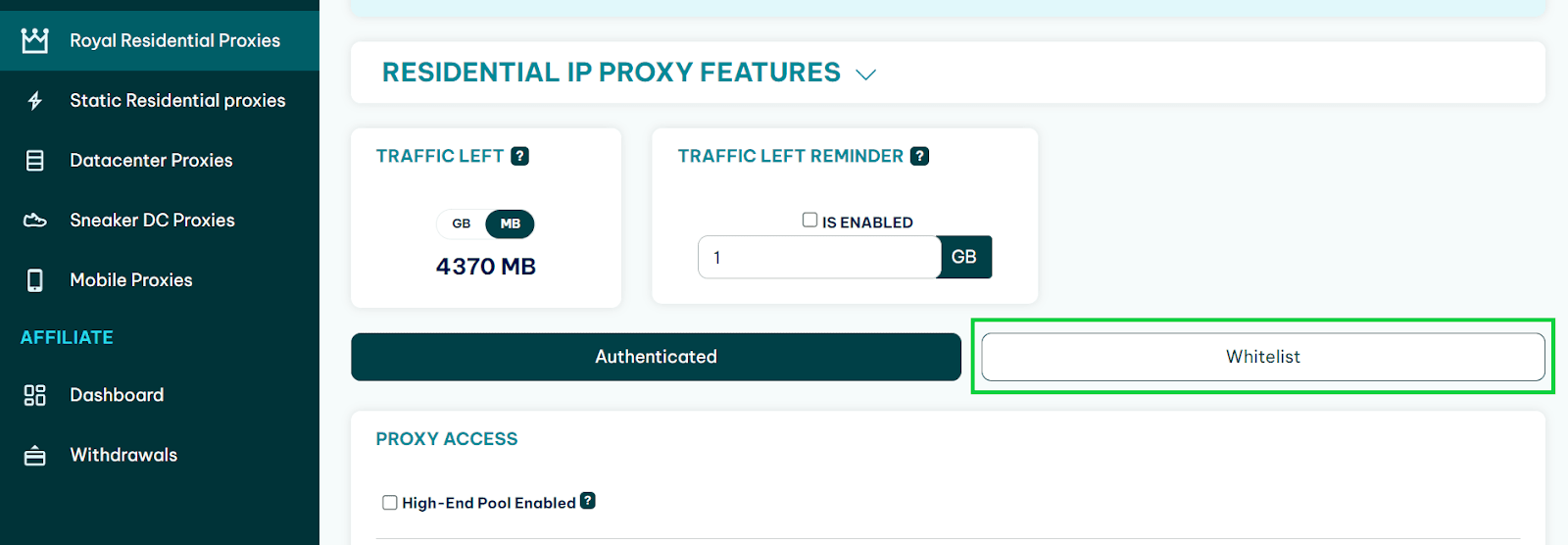
Click on the Add button.
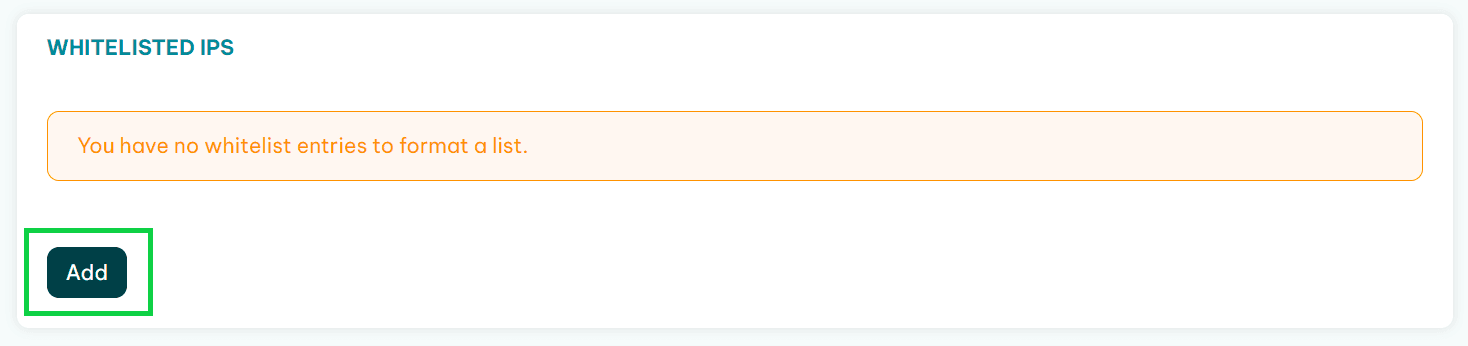
Paste in the IP and add it to the whitelist.
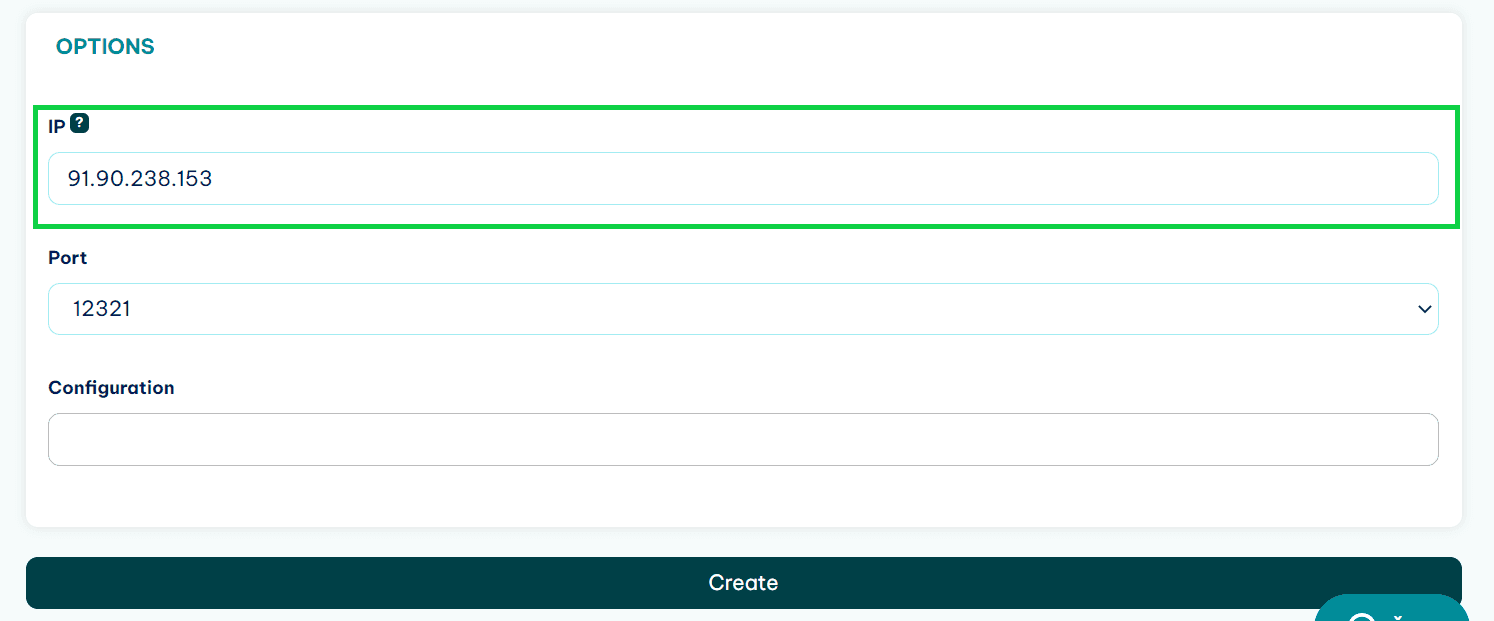
Now, when you are adding the proxy to the capabilities, use it without authentication details in the URL.
E.g. like this:
http://geo.iproyal.com:12321
And not like this:
http://username:[email protected]:12321
Since your IP is added to the whitelist, the proxy won’t ask for authorization.
Here’s a full code sample to add a proxy and test it:
use thirtyfour::{prelude::*, CapabilitiesHelper};
use tokio::time::Duration;
#[tokio::main]
async fn main() -> WebDriverResult<()> {
let mut caps = DesiredCapabilities::chrome();
caps.set_proxy(
thirtyfour::common::capabilities::desiredcapabilities::Proxy::Manual {
ftp_proxy: None,
http_proxy: Some("link-to-proxy".to_string()),
ssl_proxy: Some("link-to-proxy".to_string()),
socks_proxy: None,
socks_version: None,
socks_username: None,
socks_password: None,
no_proxy: None,
},
)?;
let driver = WebDriver::new("http://localhost:9515", caps).await?;
driver.goto("https://ipv4.icanhazip.com").await?;
let ip = driver.find(By::Css("body")).await?.text().await?;
println!("{}", ip);
driver.quit().await?;
Ok(())
}
Conclusion
While not the most frequent choice for web scraping tasks, Rust is definitely a language that can be used for this purpose. You won’t have a large ecosystem support (for example, the proxy problem is solved in Python via selenium-wire ), but it’s an interesting exercise to try it.
To practice more with the language, you can try scraping a dynamic website like Reddit where finding elements is not that simple due to auto-generated class names. Our Python Selenium tutorial can be a great guide in this.
Good luck!
FAQ
Error: NewSessionError
This error happens because ChromeDriver is not running. Run the executable that you downloaded in the setup stage and then try running Rust code again.
Error: NoSuchElement
This error happens when the library can’t locate an element. Check if the selector you’re using for the element is correct and without typos.
the trait std::fmt::Display is not implemented for impl Future<Output = Result<String, WebDriverError>>
std::fmt::Display is not implemented for impl Future<Output = Result<String, WebDriverError>> This error (and similar ones) happen because you have not added .await at the end of a statement somewhere. Because of that, a future doesn’t resolve into a real value.
Author
Gints Dreimanis
Technical Writer
Gints is a writer and software developer who’s excited about helping others learn programming. Currently the main editor of Serokell Blog , where he’s responsible for content on functional programming and machine learning.
Learn more about Gints Dreimanis

